دوره NGS منتشر شد …

Ensembl یکی از مهمترین و جامعترین دیتابیسهای ژنومیکی است که توسط مؤسسه بیوانفورماتیک اروپا (EBI) و موسسه ولکام سنگر توسعه یافته است. این پایگاه به عنوان یک منبع مرکزی برای دسترسی به اطلاعات ژنومیک گونههای مختلف از جمله انسان، موش، ماهی زبرا و بسیاری از موجودات دیگر عمل میکند. هدف اصلی Ensembl فراهم کردن دسترسی آسان به دادههای ژنومیک بهروز، توالیهای ژنی، مدلهای ژنی پیشبینیشده و اطلاعات تکاملی برای محققان است.
از زمان راهاندازی در سال ۱۹۹۹، Ensembl نقشی کلیدی در پروژه ژنوم انسان و پروژههای ژنومیک بزرگ دیگر ایفا کرده است. امروزه این پلتفرم به ابزاری ضروری برای محققان زیستشناسی مولکولی، ژنتیک پزشکی، تکامل و بیوانفورماتیک تبدیل شده است. قابلیتهای متنوع Ensembl آن را به انتخابی مناسب برای طیف وسیعی از کاربردهای تحقیقاتی از جستجوی ساده ژن تا تحلیلهای پیچیده ژنومیک تبدیل کرده است.
Ensembl در اواخر دهه ۱۹۹۰ و همزمان با پیشرفت پروژه ژنوم انسان متولد شد. تیم توسعهدهنده Ensembl با هدف ایجاد سیستمی برای حاشیهنویسی (annotation) خودکار ژنوم انسان، مدیریت دادهها و ارائه آنها از طریق یک رابط وب، این پروژه را آغاز کردند. اولین نسخه عمومی Ensembl در ژوئیه سال ۲۰۰۰ منتشر شد و تنها ژنوم انسان را پوشش میداد.
با گذشت زمان و پیشرفت فناوریهای توالییابی، Ensembl به سرعت گسترش یافت و ژنومهای بیشتری به آن اضافه شد. امروزه Ensembl شامل صدها گونه مختلف از مهرهداران تا قارچها، گیاهان و بیمهرگان است. سیستم به روزرسانی منظم Ensembl (معمولاً هر ۳ تا ۴ ماه یکبار) اطمینان میدهد که کاربران همیشه به جدیدترین اطلاعات ژنومیک دسترسی دارند. دامنه فعالیت Ensembl اکنون فراتر از مهرهداران رفته و به لطف پروژه Ensembl Genomes، اطلاعات مربوط به میکروارگانیسمها، قارچها، گیاهان و بیمهرگان را نیز در بر میگیرد.
رابط وب Ensembl به گونهای طراحی شده است که دسترسی به اطلاعات ژنومیک را برای کاربران با سطوح مختلف تخصص امکانپذیر میسازد. صفحه اصلی شامل نواری برای جستجوی نام ژنها و واریانتها، مناطق ژنومی خاص و حتی بیماریهاست. نمایش ژنوم (Genome Browser) هسته مرکزی Ensembl را تشکیل میدهد که به کاربران امکان مشاهده تصویری ژنها، ترانسکریپتها، واریانتها و سایر عناصر ژنومی را میدهد.
دیتابیس Ensembl بر اساس سیستم مدیریت پایگاهداده MySQL ساخته شده و شامل جداول متعددی برای ذخیره انواع مختلف دادههای ژنومیک است. این ساختار امکان ارسال درخواستها (query) پیچیده و بازیابی سریع اطلاعات را فراهم میکند. طراحی دیتابیس به گونهای است که بتواند حجم عظیمی از دادههای ژنومیک را مدیریت کند و در عین حال برای کاربران ساده و قابل استفاده باشد.کاربران می توانند از طریق لینک زیر به پایگاه Ensembl وارد شوند.
Ensembl طیف گستردهای از دادههای ژنومیک را ارائه میدهد. مدلهای ژنی که از ترکیب روشهای محاسباتی و شواهد تجربی به دست آمدهاند، یکی از مهمترین منابع اطلاعاتی انسمبل هستند. هر ژن میتواند شامل چندین ترانسکریپت باشد که هر کدام الگوهای متفاوتی از پیرایش متناوب را نشان میدهند. اطلاعات پروتئینی شامل دامینها، ساختار ثانویه و اطلاعات عملکردی نیز در دسترس است.
واریانتهای ژنتیکی از منابع مختلف مانند پروژه ۱۰۰۰ ژنوم، gnomAD و دیتابیسهای اختصاصی بیماریها در Ensembl ادغام شدهاند. اطلاعات تنظیمی شامل جایگاههای اتصال فاکتورهای رونویسی، نواحی حساس به DNase و تغییرات هیستونی از پروژههایی مانند ENCODE و Roadmap Epigenomics جمعآوری شدهاند. دادههای مقایسهای و تکاملی مانند همردیفیهای چندگانه، درختهای فیلوژنی و ژنهای همولوگ نیز از دیگر منابع ارزشمند Ensembl هستند.
BioMart یکی از قدرتمندترین ابزارهای Ensembl برای استخراج حجم عظیمی از دادههای ژنومی است. این سیستم به کاربران امکان میدهد تا دادهها را با معیارهای مختلف فیلتر کرده و خروجی را بر اساس نیاز خود سفارشیسازی نمایند. رابط کاربری آن شامل مراحل مشخصی برای انتخاب پایگاه داده، اعمال فیلترها و تعیین ویژگیهای خروجی (Attributes) است.
برای مثال، میتوانید به سادگی با انتخاب دیتابیس ژنهای انسان، فیلتر کردن نتایج بر اساس کروموزوم ۱ و سپس تعیین خروجی برای دریافتGene stable ID (شناسه Ensembl) و Gene name (اسم ژن)، لیستی کامل از ژنهای این کروموزوم را استخراج نمایید.
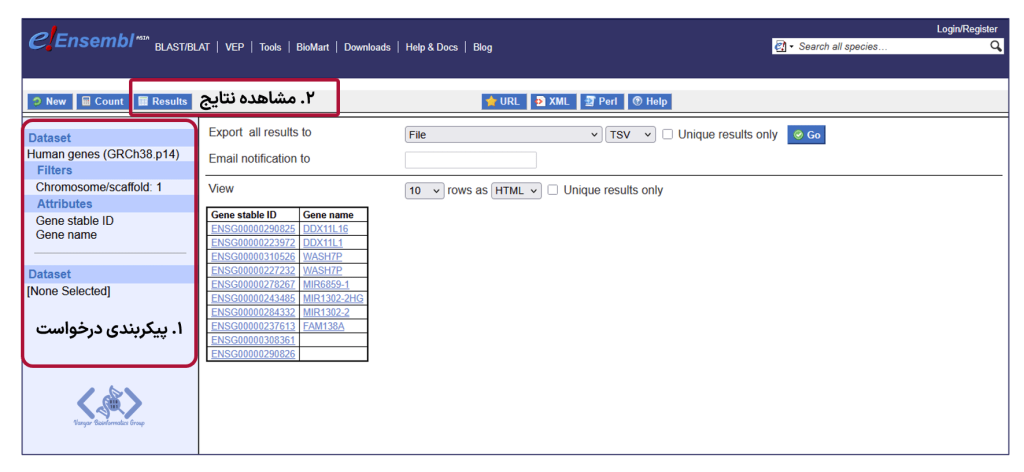
این ابزار که به صورت تحت وب و همچنین از طریق API های Perl، R (با بسته biomaRt) و REST قابل دسترسی است، برای مطالعات ژنومی در مقیاس بزرگ، آنالیزهای ترانسکریپتومیکس و پروتئومیکس بسیار کارآمد است، زیرا امکان استخراج همزمان دادههای متنوع برای هزاران ژن را فراهم میکند.
Variant Effect Predictor یا VEP ابزاری قدرتمند برای تعیین تأثیر واریانتهای ژنتیکی بر ژنها، ترانسکریپتها و توالیهای پروتئینی است. این ابزار میتواند تأثیرات جهشهای نقطهای، حذفها، اضافهها و سایر تغییرات ژنتیکی را پیشبینی کند. VEP قادر است نتایج را با اطلاعات از منابع خارجی مانند ClinVar، SIFT، PolyPhen و CADD غنیسازی کند تا دید جامعتری از اهمیت بالینی واریانتها ارائه دهد.
محققان از VEP در مطالعات ژنتیک بیماریها، تحلیل دادههای توالییابی نسل جدید و پروژههای پزشکی دقیق استفاده میکنند. این ابزار از طریق رابط وب، خط فرمان و API قابل دسترسی است و میتواند دادههای حجیم حاوی میلیونها واریانت را پردازش کند. یکی از ویژگیهای مهم VEP توانایی آن در تحلیل واریانتها در زمینه ایزوفرمهای مختلف یک ژن است که برای درک جامع تأثیر واریانتها بسیار مهم است.
Ensembl مجموعهای غنی از ابزارها برای مطالعات تکاملی و مقایسهای ارائه میدهد. ابزار Compara امکان مقایسه ژنومهای مختلف، شناسایی ژنهای همولوگ (اورتولوگ و پارالوگ) و بررسی حفاظتشدگی توالیها را فراهم میکند. میتوانید ساختار ژنهای مشابه را در گونههای مختلف مقایسه کنید و نواحی حفاظتشده را شناسایی نمایید که احتمالاً از نظر عملکردی اهمیت دارند.
همردیفیهای ژنومی چندگانه برای شناسایی عناصر تکاملی حفاظتشده در گونههای مختلف بسیار ارزشمند هستند. این اطلاعات به محققان کمک میکند تا نواحی عملکردی مهم را که در طول تکامل حفظ شدهاند، شناسایی کنند. درختهای فیلوژنی در انسمبل روابط تکاملی بین ژنهای مختلف را نشان میدهند و میتوانند در مطالعات مربوط به تکامل خانوادههای ژنی و شناسایی وقایع دوتاییشدگی ژنوم بسیار مفید باشند.
بیایید با هم سفری کوتاه را شروع کنیم: فرض کنید میخواهیم ژن CYP1A2 را که در متابولیسم کافئین در بدن نقش دارد، پیدا کرده، ساختار آن را روی کروموزوم ببینیم و در نهایت توالی پروتئین آن را دانلود کنیم.
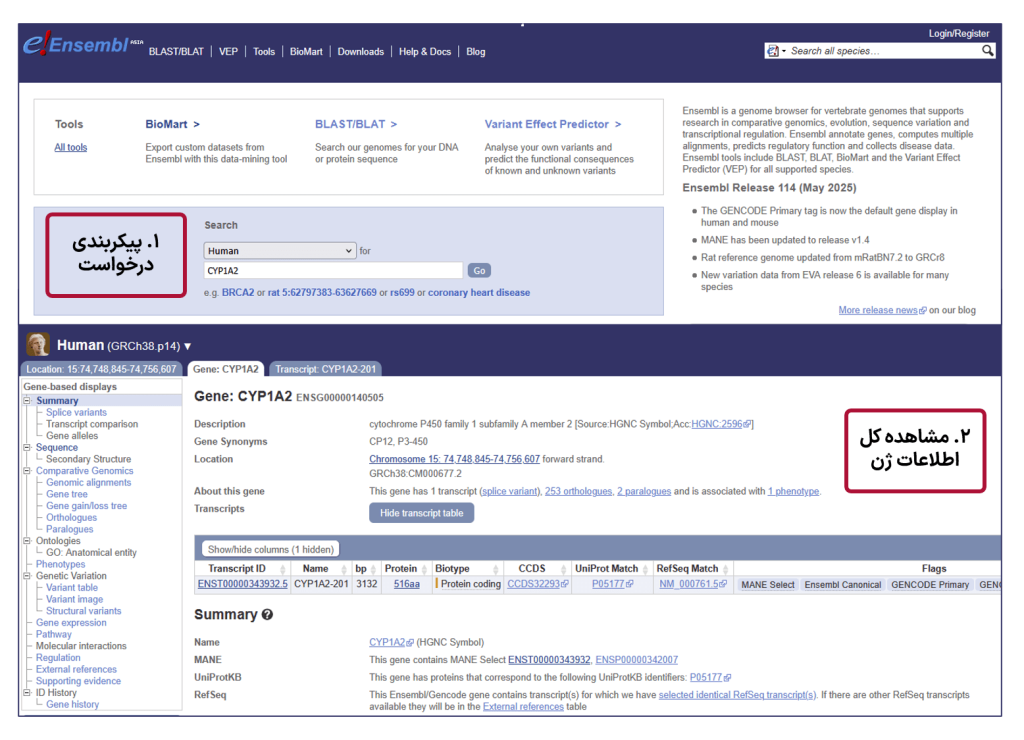
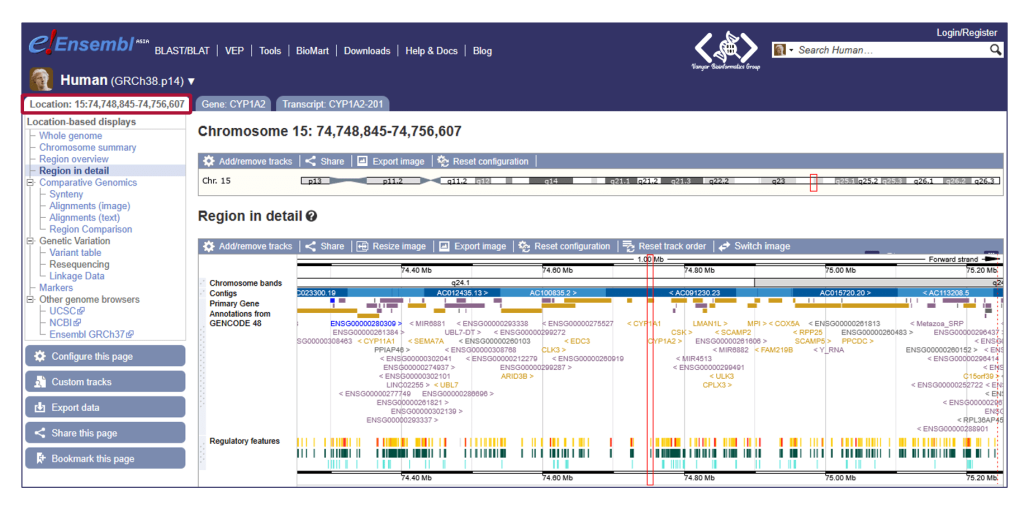
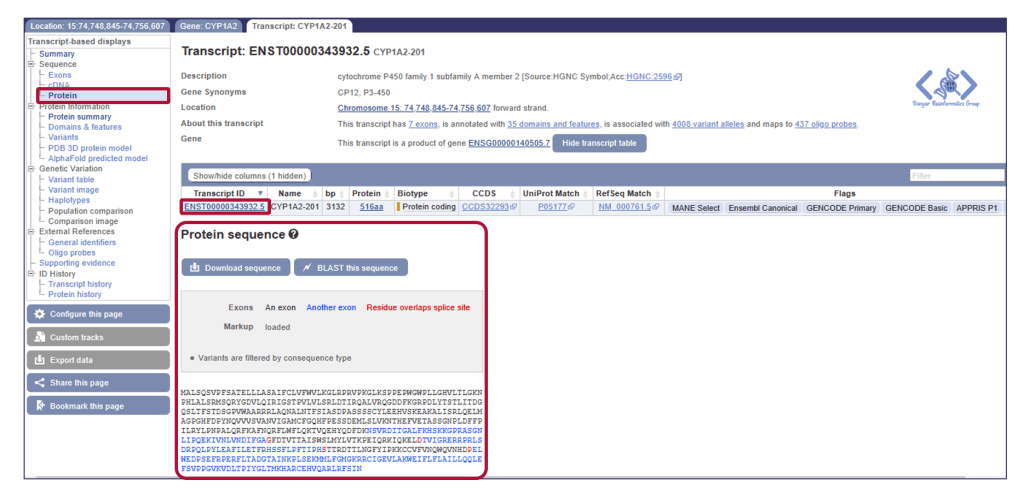
این مثال یک روش سریع برای کار با یک ژن بود. اما قدرت واقعی Ensembl در کارهای مقیاس بزرگ مشخص میشود.
Ensembl نقش مهمی در تحقیقات مرتبط با ژنتیک بیماریها ایفا میکند. محققان میتوانند از این پایگاه برای شناسایی واریانتهای مرتبط با بیماری، بررسی ژنهای کاندید و تفسیر نتایج مطالعات ارتباط ژنومی (GWAS) استفاده کنند. ابزار VEP به طور خاص برای ارزیابی تأثیر واریانتهای ژنتیکی بر عملکرد ژنها و خطر بیماریها بسیار مفید است. این ابزار واریانتها را با دیتابیسهای مرتبط با بیماری مانند ClinVar و OMIM انوتیت میکند.
در مطالعات پزشکی دقیق، انسمبل امکان بررسی تنوع ژنتیکی در جمعیتهای مختلف را فراهم میکند. دادههای فراوانی آللها از پروژههای بزرگی مانند gnomAD، 1000 genomes و UK10K در Ensembl ادغام شدهاند. این اطلاعات به محققان کمک میکند تا نادر یا شایع بودن واریانتهای خاص را در جمعیتهای مختلف ارزیابی کنند. همچنین، امکان بررسی ساختار ژنهای مسئول بیماریهای ژنتیکی و شناسایی موتیفهای عملکردی مهم را فراهم میکند.
Ensembl مجموعه غنی از دادهها و ابزارها برای مطالعات تکاملی و فیلوژنتیک ارائه میدهد. ابزارهای Compara امکان شناسایی ژنهای همولوگ (اورتولوگ و پارالوگ) در گونههای مختلف را فراهم میکنند. درختهای فیلوژنتیک برای هر ژن، تاریخچه تکاملی آن را نشان میدهند و به محققان کمک میکنند تا رویدادهای مهم مانند دوتاییشدگی ژن را شناسایی کنند. این اطلاعات برای درک چگونگی تکامل ژنها و عملکردهای جدید آنها بسیار ارزشمند است.
همردیفیهای ژنومی چندگانه (Multiple Genome Alignment) در Ensembl برای شناسایی عناصر حفاظتشده تکاملی استفاده میشوند. این عناصر معمولاً نشاندهنده نواحی عملکردی مهم هستند که در طول تکامل حفظ شدهاند. Ensembl همچنین امکان مقایسه ساختار ژنومی در گونههای مختلف را فراهم میکند که برای مطالعات تکامل ژنوم و بازآراییهای کروموزومی مفید است. تحلیلهای مبتنی بر نسبت dN/dS (نرخ واریانتهای non-synonymous به synonymous) برای شناسایی ژنهایی که تحت انتخاب مثبت یا منفی بودهاند، در Ensembl قابل دسترسی است.
Ensembl برای مطالعات ژنومیک عملکردی و بیان ژن منبع ارزشمندی است. اطلاعات مربوط به ساختار ژن، ایزوفرمهای مختلف حاصل از پیرایش متناوب و عناصر تنظیمی برای طراحی آزمایشهای عملکردی ضروری هستند. دادههای بیانی از منابع مختلف مانند GTEx و Expression Atlas در Ensembl ادغام شدهاند تا الگوهای بیان ژنها در هر بافت را نشان دهند. این اطلاعات برای شناسایی ژنهای کاندید در بافتهای خاص بسیار مفید است.
عناصر تنظیمی شناسایی شده توسط پروژههایی مانند ENCODE و Roadmap Epigenomics در Ensembl قابل مشاهده هستند. این عناصر شامل افزایندهها (enhancers)، خاموشکنندهها (silencers)، مناطق اتصال فاکتورهای رونویسی و نواحی حساس به DNase هستند. Ensembl همچنین پیشبینیهایی در مورد تأثیر عملکردی واریانتها بر بیان ژن ارائه میدهد. این اطلاعات برای درک چگونگی تنظیم بیان ژن در شرایط مختلف و نقش واریانتهای تنظیمی در بیماریها بسیار ارزشمند است.
پایگاه Ensembl و UCSC Genome Browser دو پایگاهداده اصلی ژنومی هستند که هر کدام مزایا و رویکردهای متفاوتی دارند. Ensembl روی حاشیهنویسی ژن با استفاده از روشهای پیشبینی محاسباتی و شواهد تجربی تمرکز دارد و مجموعه دادههای جامعی برای مطالعات مقایسهای ژنومی و تکاملی ارائه میدهد. در مقابل، UCSC بیشتر به عنوان یک مرورگر ژنومی طراحی شده است که طیف وسیعی از دادههای آزمایشگاهی را ادغام میکند و برای مشاهده تصویری دادههای ژنومی بسیار مناسب است.
از نظر رابط کاربری، UCSC رویکرد سنتیتری دارد که برای کاربران با تجربه آشناتر است، در حالی که Ensembl رابط مدرنتری ارائه میدهد که ناوبری بین صفحات مختلف را آسانتر میکند. انسمبل API های قویتری برای دسترسی برنامهنویسی به دادهها ارائه میدهد، در حالی که UCSC امکانات بیشتری برای آپلود و نمایش دادههای شخصی کاربران دارد. انتخاب بین این دو پلتفرم به نیازهای خاص پژوهشی بستگی دارد و بسیاری از محققان از هر دو منبع استفاده میکنند.
Ensembl و دیتابیسهای NCBI (مانند RefSeq و Gene) دو منبع مهم برای اطلاعات ژنومی هستند که رویکردهای متفاوتی در حاشیهنویسی ژن دارند. RefSeq بر کیفیت و دقت بالا در حاشیهنویسی ژن تمرکز دارد و معمولاً برای هر ژن فقط ایزوفرمهای تأیید شده را ارائه میدهد. در مقابل، Ensembl رویکرد جامعتری دارد و سعی میکند تمام ترانسکریپتهای ممکن را با ترکیبی از شواهد تجربی و پیشبینیهای محاسباتی شناسایی کند.
شناسهها در این دو سیستم متفاوت هستند. برای مثال، Ensembl از شناسههایی مانند ENSG برای ژنها استفاده میکند، در حالی که سیستم NCBI از شناسههای عددی در دیتابیس Gene (مانند Gene ID) و شناسههایی با پیشوند (مانند NM برای mRNA و NP برای پروتئین) در دیتابیس RefSeq بهره میبرد. البته Ensembl ابزارهایی برای تبدیل این شناسهها به یکدیگر فراهم میکند. NCBI پوشش گستردهتری از گونهها دارد، در حالی که Ensembl اطلاعات عمیقتری برای گونههای تحت پوشش خود ارائه میدهد. هر دو پایگاه به طور مداوم با یکدیگر همکاری میکنند و دادهها را به اشتراک میگذارند تا اطلاعات جامعتری برای جامعه علمی فراهم کنند.
Ensembl به طور مداوم در حال تکامل و بهبود است تا با پیشرفتهای سریع در ژنومیک همگام باشد. در سالهای اخیر، بهبودهای قابل توجهی در رابط کاربری وب ایجاد شده است تا کارایی و تجربه کاربری بهبود یابد. همچنین پشتیبانی از دادههای تکسلولی و چندانسانی (multi-human) به Ensembl اضافه شده است که منعکسکننده جهتگیریهای جدید در تحقیقات ژنومیک است. ادغام دادههای اپیژنومیک و تنظیمی گستردهتر نیز از دیگر پیشرفتهای اخیر است.
در آینده، انتظار میرود Ensembl تمرکز بیشتری بر ژنومیک جمعیتی و تنوع ژنتیکی داشته باشد. با افزایش تعداد ژنومهای توالییابی شده، ارائه و تفسیر این حجم عظیم از تنوع ژنتیکی چالش بزرگی خواهد بود. همچنین، ادغام دادههای عملکردی از فناوریهای جدید مانند CRISPR و تصویربرداری ژنومی میتواند درک ما از عملکرد ژنها را عمیقتر کند. بهبود ابزارهای محاسباتی برای تفسیر واریانتها و پیشبینی فنوتیپ از دیگر زمینههایی است که احتمالاً در توسعههای آینده Ensembl مورد توجه قرار خواهد گرفت.
Ensembl در حال تطبیق با فناوریهای نوظهور در زمینه ژنومیک است. یکی از این زمینهها، توالییابی خوانشهای بلند (long-read) است که امکان حاشیهنویسی دقیقتر ژنوم، به ویژه در مناطق تکراری و پیچیده را فراهم میکند. Ensembl در حال توسعه روشهایی برای یکپارچهسازی و نمایش این دادههای جدید است که میتواند به شناسایی بهتر ساختارهای ژنی پیچیده و واریانتهای ساختاری کمک کند.
ادغام دادههای تکسلولی (single-cell) از دیگر زمینههای مهم است. این دادهها اطلاعات ارزشمندی درباره تنوع بیان ژن در سطح سلولی ارائه میدهند که برای درک بهتر عملکرد ژنها در بافتها و شرایط مختلف ضروری است. همچنین، پیشرفتهای اخیر در یادگیری ماشین و هوش مصنوعی فرصتهای جدیدی برای پیشبینی و تفسیر دادههای ژنومیک فراهم کرده است. Ensembl در حال بررسی روشهایی برای ادغام این فناوریها در پلتفرم خود است تا قدرت پیشبینی و تفسیر دادهها را افزایش دهد.
Ensembl به عنوان یکی از مهمترین منابع ژنومیک، نقشی حیاتی در پیشرفت تحقیقات زیستی و پزشکی ایفا میکند. قدرت این پلتفرم در یکپارچهسازی حجم عظیمی از دادههای ژنومیک، ارائه ابزارهای تحلیلی قدرتمند و فراهم کردن دسترسی آسان به این اطلاعات از طریق رابطهای کاربری متنوع است. با گسترش روزافزون دادههای ژنومی، نقش Ensembl در سازماندهی، تفسیر و ارائه این دادهها به شکلی قابل استفاده برای محققان، اهمیت بیشتری پیدا میکند.
در عصر پزشکی دقیق و ژنومیک شخصی، پایگاههایی مانند Ensembl پل ارتباطی بین دیتای خام ژنومیک و کاربردهای بالینی هستند. آشنایی با Ensembl و توانایی استفاده مؤثر از آن برای تمام محققان در زمینههای زیستشناسی مولکولی، ژنتیک پزشکی، تکامل و بیوانفورماتیک ضروری است.
🎇 امیدواریم این آموزش توانسته باشد دید جالبی از قابلیتها و کاربردهای Ensembl را به شما ارائه دهد و به عنوان نقطه شروعی برای کاوش بیشتر در این پلتفرم ارزشمند عمل کند.
پیشنهاد: از آموزک Bioconda چیست؟ معرفی و آموزش Bioconda بازدید کنید.
Ensembl یک دیتابیس ژنومیک است که اطلاعات جامع و بهروز درباره ژنومهای موجودات مختلف، شامل انسان، موش، ماهی زبرا و بسیاری دیگر را ارائه میدهد. این پایگاهداده ابزارهایی برای تحلیل دادههای ژنومی، مقایسه گونهها و پیشبینی اثرات واریانتهای ژنتیکی دارد.
برای جستجو در Ensembl، میتوانید از نوار جستجوی اصلی استفاده کنید و نام ژن، شناسه Ensembl، موقعیت کروموزومی یا شناسه UniProt را وارد کنید. سپس صفحهای شامل اطلاعات جامع درباره ژن یا منطقه ژنومی مورد نظر نمایش داده میشود.
BioMart یک ابزار قدرتمند در Ensembl است که امکان استخراج دادههای ژنومی در حجم بالا و به صورت سفارشی را فراهم میکند. این ابزار برای فیلتر کردن دیتا و استخراج اطلاعات مرتبط با ژنها، ترانسکریپتها، مسیرهای زیستی و واریانتها استفاده میشود.
VEP یک ابزار تحلیل در Ensembl است که اثر واریانتهای ژنتیکی را بر ژنها، ترانسکریپتها و توالیهای پروتئینی پیشبینی میکند. این ابزار برای مطالعات مرتبط با بیماریهای ژنتیکی و پزشکی دقیق بسیار کاربردی است.
Ensembl و UCSC Genome Browser هر دو پایگاه دادههای ژنومی هستند. Ensembl ابزارهای گستردهای برای حاشیهنویسی ژن، پیشبینی واریانتها و تحلیل تکاملی ارائه میدهد، در حالی که UCSC بیشتر برای مشاهده تصویری دادههای ژنومی و ادغام دادههای آزمایشگاهی مناسب است.

تیم تولید محتوای گروه بیوانفورماتیک وانیار در تلاش است تا بهترین آموزشهای کوتاه در زمینه بیوانفورماتیک و زیستشناسی را تهیه نماید. صحت محتوای این صفحه توسط کارشناسان گروه بیوانفورماتیک وانیار بررسی شده است.



عضویت در مجله وانیار
جدید ترین مقالات در ایمیل شما!
با عضویت در مجله بیوانفورماتیک وانیار ، برترین مقالات را در ایمیل خود دریافت کنید.
سلام، وقت بخیر.
چطور میتونیم بهتون کمک کنیم؟ 🤓
تیم ما آماده پاسخگویی به سوالات شماست.
پشتیبانی 24 ساعته در 7 روز هفته.







