دوره NGS منتشر شد …

نرمافزار T-Coffee یا Tree-based Consistency Objective Function For alignment Evaluation، به عنوان یکی از قدرتمندترین و انعطافپذیرترین راهکارها برای همردیفسازی چندگانه توالی (MSA) شناخته میشود. این نرمافزار که توسط سدریک نوتردام و همکارانش در سال 2000 معرفی شد، با ارائه روشی نوآورانه برای ترکیب اطلاعات از منابع مختلف، دقت همردیفسازی (Alignment) را به طور قابل توجهی افزایش داده است.
T-Coffee به عنوان انقلابی در عرصه MSA ظهور کرد. این الگوریتم در پاسخ به محدودیتهای روشهای سنتی مانند ClustalW توسعه یافت که اغلب در مواجهه با توالیهای دارای تشابه کم، با چالشهای جدی روبرو میشدند. نوآوری اصلی T-Coffee استفاده از روش “مبتنی بر سازگاری” (consistency-based) بود که برای اولین بار امکان ترکیب نتایج حاصل از روشهای مختلف همردیفسازی را فراهم کرد. از زمان انتشار اولیه، T-Coffee مسیر تکاملی قابل توجهی را طی کرده است و نسخههای متعددی از آن برای کاربردهای خاص توسعه یافتهاند. امروزه، این نرمافزار به عنوان یکی از ارکان اصلی پژوهشهای بیوانفورماتیک و زیستشناسی محاسباتی شناخته میشود و هزاران استناد در مقالات علمی دارد.
الگوریتم T-Coffee بر یک استراتژی هوشمندانه دو مرحلهای استوار است: ابتدا یک کتابخانه از الاینمنتهای دوتایی بر اساس منابع مختلف ایجاد میکند و سپس از وزنهای این کتابخانه برای هدایت یک فرآیند همردیفی پیشرونده (Progressive Alignment) استفاده مینماید.
قلب الگوریتم T-Coffee، رویکرد منحصر به فرد آن در ایجاد یک “کتابخانه اولیه” (Primary Library) است. این کتابخانه، مجموعهای از همردیفیهای دوتایی (Pairwise Alignments) است که نه تنها از مقایسه مستقیم توالیهای ورودی، بلکه از منابع خارجی مانند خروجی سایر الگوریتمها (نظیر ClustalW و MAFFT) یا حتی اطلاعات ساختاری سهبعدی (در حالت 3D-Coffee) نیز گردآوری میشود. سپس، به هر جفت آمینواسید یا نوکلئوتید همردیفشده در این کتابخانه، یک “امتیاز سازگاری” (Consistency Score) اختصاص مییابد. این امتیاز بر اساس مفهوم انتقالپذیری (Transitivity) محاسبه میشود؛ به این معنی که امتیاز یک جفت (مثلاً A-B) با توجه به میزان توافق آن با سایر همردیفیهای مرتبط در کتابخانه (مانند A-C و C-B) تقویت یا تضعیف میگردد.
پس از ساخت کتابخانه وزندار، T-Coffee از آن به عنوان یک راهنمای دقیق برای هدایت یک فرآیند همردیفی پیشرونده (Progressive Alignment) استفاده میکند. این فرآیند مشابه روشهای کلاسیک، با ساخت یک درخت راهنما (Guide Tree) آغاز شده و سپس توالیها و پروفایلها بر اساس ترتیب انشعابات درخت، با یکدیگر همردیف میشوند. تفاوت کلیدی در اینجاست: در مرحله برنامهنویسی پویا (Dynamic Programming)، به جای استفاده از ماتریسهای جایگزینی استاندارد (مانند BLOSUM)، الگوریتم از امتیازات سازگاری که در مرحله قبل محاسبه شدهاند، برای امتیازدهی به همردیفیها بهره میبرد. در نتیجه، هدف نهایی، یافتن همردیفی چندگانهای است که مجموع امتیازات سازگاری آن با کتابخانه اولیه، حداکثر شود. این رویکرد، دقت همردیفی را بهویژه برای توالیهایی با تشابه کم که سیگنال تکاملی ضعیفی دارند، به طور چشمگیری افزایش میدهد.
قدرت اصلی تی-کافی در تولید همردیفیهای بسیار دقیق، آن را به ابزاری کلیدی برای انواع پژوهشهای ساختاری، عملکردی و تکاملی تبدیل کرده است. این ابزار به دلیل انعطافپذیری بالا، برای تحلیل پروتئینها، RNA و DNA به کار میرود.

یکی از متداولترین کاربردهای T-Coffee، همردیفسازی توالیهای پروتئینی است. این نرمافزار بهویژه در مورد پروتئینهایی با تشابه متوسط تا کم (30 تا 50%) عملکرد بسیار خوبی دارد. محققان از T-Coffee برای شناسایی دومینهای حفاظتشده، موتیفهای عملکردی و آمینواسیدهایی استفاده میکنند که برای تاشدگی یا عملکرد پروتئین ضروری هستند. یک ویژگی منحصربهفرد تی-کافی در این زمینه، توانایی آن در تلفیق اطلاعات ساختاری (از طریق ماژول 3D-Coffee) با اطلاعات توالی است. این امر به تولید همردیفیهایی با دقت بالاتر منجر میشود، بهخصوص در مناطقی که ساختار سهبعدی بیشتر حفاظتشده است تا توالی اولیه. تی-کافی همچنین قادر است امتیاز اطمینان برای هر موقعیت در همردیفی تولید کند که به محققان در ارزیابی کیفیت الاینمنت کمک میکند.
علاوه بر پروتئینها، T-Coffee برای همردیفسازی توالیهای نوکلئوتیدی نیز کاربرد دارد. R-Coffee، یک نسخه تخصصی از T-Coffee، به طور خاص برای تحلیل RNA طراحی شده است و میتواند ساختار ثانویه RNA را در فرآیند همردیفسازی لحاظ کند. این قابلیت برای مطالعه RNAهای غیرکدکننده، ریبوزیمها و سایر مولکولهای RNA که عملکردشان به ساختار آنها وابسته است، بسیار ارزشمند میباشد. برای توالیهای DNA، برنامه T-Coffee میتواند در تحلیل نواحی ژنی کوتاه، مانند نواحی تنظیمی، اینترونها و اگزونها برای شناسایی عناصر حفاظتشده بسیار مفید باشد. با این حال، به دلیل پیچیدگی محاسباتی بالا، این نرمافزار برای همردیفسازی توالیهای بسیار بلند مانند کروموزومها یا ژنومهای کامل مناسب نیست.
T-Coffee نقش مهمی در مطالعات فیلوژنتیک ایفا میکند، زیرا کیفیت MSA تأثیر مستقیمی بر دقت درخت فیلوژنتیک حاصلشده دارد. همردیفیهای دقیقتر منجر به تخمین بهتر روابط تکاملی بین گونهها میشوند. تی-کافی با ارائه الاینمنتهای با دقت بالا و امتیازهای اطمینان برای هر موقعیت، به محققان کمک میکند مناطق با اطمینان بالا را برای تحلیلهای فیلوژنتیک انتخاب کنند. این نرمافزار همچنین قابلیت ایجاد خروجی در قالبهای مختلف از جمله PHYLIP، Clustal و FASTA را دارد که با اکثر نرمافزارهای فیلوژنتیک سازگار هستند. علاوه بر این، وزندهی مناسب به مناطق محافظتشده توسط تی-کافی میتواند به بهبود تحلیلهای فیلوژنتیک بعدی کمک کند.
برای بهرهبردن از قدرت الگوریتمی T-Coffee، دو دروازه اصلی وجود دارد که هر دو به یک موتور پردازشی یکسان و قدرتمند منتهی میشوند. انتخاب دروازه، تنها به سبک کار و نیاز شما بستگی دارد:
۱: پورتال آنلاین T-Coffee (مسیر سریع و هوشمند) – ۲: نسخه خط فرمان (کنترل کامل برای متخصصان)
بهترین و سادهترین نقطه شروع برای کار با T-Coffee، استفاده از وبسرور کاربرپسند آن است. در این راهنمای عملی، قدم به قدم یک همردیفی علمی را انجام میدهیم تا ببینیم چگونه میتوان روابط تکاملی و نواحی عملکردی حفاظتشده بین پروتئینهای خانواده گلوبین را شناسایی کرد.
هدف : ما قصد داریم توالی پروتئینی زیرواحد آلفای Hemoglobin و Myoglobin از انسان را با Leghemoglobin از یک گیاه (سویا) همردیف کنیم. هر سه پروتئین به خانواده بزرگ گلوبینها تعلق دارند و وظیفه انتقال اکسیژن را بر عهده دارند، اما در طول تکامل از یکدیگر فاصله گرفتهاند. هدف ما، پیدا کردن آمینواسیدهای کلیدی است که با وجود میلیونها سال تکامل، همچنان حفاظتشده باقی ماندهاند.
ابتدا، توالیهای مورد نظر را در فرمت FASTA آماده میکنیم :
>HBA_HUMAN Hemoglobin subunit alpha
MVLSPADKTNVKAAWGKVGAHAGEYGAEALERMFLSFPTTKTYFPHFDLSHGSAQVKGHG
KKVADALTNAVAHVDDMPNALSALSDLHAHKLRVDPVNFKLLSHCLLVTLAAHLPAEFTP
AVHASLDKFLASVSTVLTSKYR
>MYG_HUMAN Myoglobin
MGLSDGEWQLVLNVWGKVEADIPGHGQEVLIRLFKGHPETLEKFDKFKHLKSEDEMKASE
DLKKHGATVLTALGGILKKKGHHEAEIKPLAQSHATKHKIPVKYLEFISECIIQVLQSKHP
GDFGADAQGAMNKALELFRKDIAAKYKELGYQG
>LGB2_SOYBN Leghemoglobin
MVAFTEKQEALVSSSFEAFKANIPQYSVVFYTSILEKAPAAKDLFSFLANGVDPTNPKLT
GHAEKLFALVRDSAGQLKASGTVVADAALGSVHAQKAVTDPQFVVVKEALLKTIKEAVGD
WSDELSSAWEVAYDELAAAIKKAمرورگر خود را باز کرده و به پورتال آنلاین این ابزار مراجعه کنید. شما با یک صفحه اصلی مواجه میشوید که سه انتخاب را پیش روی شما قرار میدهد: PROTEINS | RNA | DNA.
با بردن ماوس بر روی هر کدام از این گزینهها، مجموعهای از حالتهای تخصصی نمایان میشود. برای مثال:
Expresso) یا ترکیب نتایج سایر الگوریتمها (M-Coffee) وجود دارد.R-Coffee, SARA-Coffee) دیده میشود.M-Coffee) یا تحلیل نواحی پروموتر (Pro-Coffee) فراهم شده است.برای پیشبرد هدف این مثال، روی T-COFFEE SIMPLE MSA کلیک کنید. این دکمه شما را به صفحه همردیفی ساده و اصلی هدایت میکند که برای هر سه نوع توالی (پروتئین، RNA و DNA) به صورت استاندارد عمل میکند.
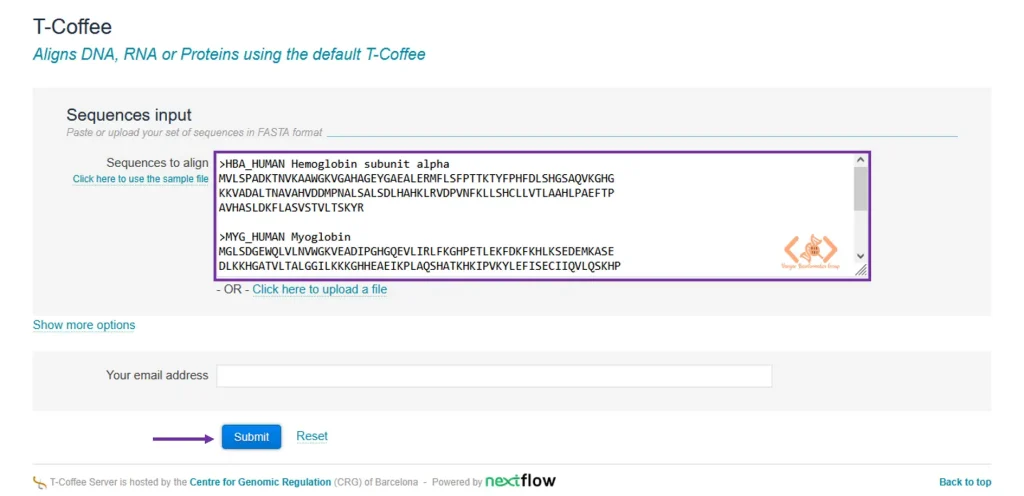
این صفحه آماده دریافت توالیهای شما است. حالا مراحل زیر را به ترتیب انجام دهید:
Sequences input)، توالیهای خانواده گلوبین را که در مرحله ۱ آماده کردید، به طور کامل Paste کنید.Your email address میتوانید ایمیل خود را وارد کنید. اگر این کار را انجام دهید، پس از اتمام پردازش، لینک صفحه نتایج برایتان ارسال میشود. این کار برای تحلیلهایی که ممکن است زمانبر باشند، بسیار مفید است.Submit کلیک کنید.حالا سرور T-Coffee شروع به پردازش دادههای شما میکند. پس از چند لحظه، به صورت خودکار به صفحه نتایج منتقل خواهید شد.
اولین و مهمترین بخشی که در صفحه نتایج مشاهده میکنید، خودِ MSA است.
BAD (آبی) تا GOOD (قرمز) وجود دارد. رنگ هر آمینواسید در همردیفی، نشاندهنده امتیاز اطمینان T-Coffee به صحت قرارگیری آن در آن ستون است.cons وجود دارد. علامت * یعنی تمام توالیها در آن ستون یکسان هستند (حفاظتشدگی کامل).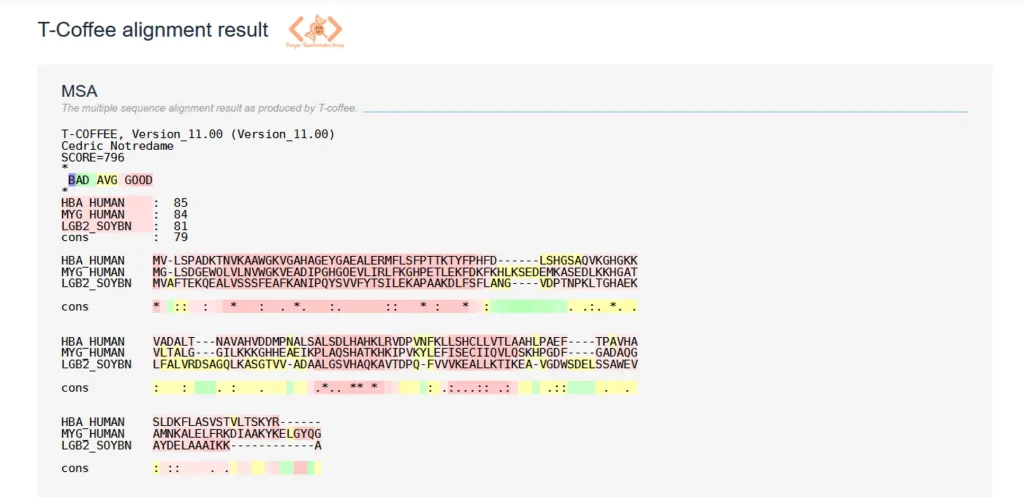
با اسکرول کردن به پایین صفحه، به بخش Result files میرسید. اینجا مخزن تمام دیتای تولیدشده برای تحلیل شماست.
score_html file: همین صفحه نتایج بصری که در حال مشاهده آن هستید.clustalw_aln file یا fasta_aln file: فایل همردیفی در فرمت متنی استاندارد که میتوانید آن را در نرمافزارهای دیگر (مانند نرمافزارهای ساخت درخت فیلوژنتیک) استفاده کنید.dnd file: فایل درخت راهنما (dendrogram) که T-Coffee برای انجام همردیفی پیشرونده از آن استفاده کرده است.😎 تبریک! شما با موفقیت یک تحلیل کامل را از ابتدا تا انتها با وبسرور T-Coffee انجام دادید و اکنون با بخشهای اصلی صفحه نتایج آن برای یک تحلیل علمی دقیق آشنا هستید.
فراتر از همردیفی استاندارد، قدرت واقعی T-Coffee در چارچوب انعطافپذیر آن نهفته است که برای حل چالشهای خاص بیوانفورماتیکی، به نسخههای تخصصی و هوشمندی مجهز شده است. این ماژولها با ادغام انواع دادههای ساختاری و الگوریتمی، دقت همردیفی را به سطح جدیدی ارتقا میدهند.
3D-Coffee یکی از قدرتمندترین نسخههای تخصصی T-Coffee است که امکان تلفیق اطلاعات ساختار سهبعدی پروتئینها را در فرآیند همردیفسازی فراهم میکند. این ویژگی بهویژه برای پروتئینهایی با تشابه توالی پایین اما ساختار محافظتشده بسیار ارزشمند است. 3D-Coffee میتواند فایلهای PDB را به عنوان ورودی دریافت کند و از همردیفیهای ساختاری تولید شده توسط ابزارهایی مانند SAP و TM-align در ساخت کتابخانه همردیفی اولیه استفاده کند. مطالعات نشان دادهاند که در بسیاری موارد، استفاده از اطلاعات ساختاری میتواند دقت همردیفی را به میزان قابل توجهی افزایش دهد. این رویکرد برای مطالعات مدلسازی همولوژی، طراحی پروتئین و مهندسی آنزیم بسیار کاربردی است، زیرا اطلاعات ساختاری اغلب بهتر از توالی حفظ میشوند و بینش عمیقتری در مورد ارتباطات عملکردی فراهم میکنند.
R-Coffee نسخه تخصصیای از T-Coffee است که برای همردیفسازی توالیهای RNA طراحی شده است. این نسخه قادر است ساختار ثانویه RNA را در فرآیند همردیفسازی لحاظ کند، که برای مولکولهایی مانند RNA اهمیت زیادی دارد زیرا عملکرد RNA اغلب به ساختار آن وابسته است نه توالی دقیق نوکلئوتیدها. R-Coffee از ابزارهای پیشبینی ساختار RNA مانند RNAfold یا RNAlifold استفاده میکند تا اطلاعات ساختاری را در کتابخانه همردیفی خود وارد کند. این رویکرد بهویژه برای RNAهای غیرکدکننده، RNAهای ریبوزومی، RNAهای راهنما (guide RNAs) و سایر RNAهای عملکردی که ساختار آنها نقش مهمی در عملکردشان دارد، بسیار مفید است. مطالعات نشان دادهاند که R-Coffee در مقایسه با روشهای استاندارد همردیفسازی، همردیفیهایی با دقت بسیار بالاتر برای RNAها تولید میکند.
M-Coffee (Meta-Coffee) یک رویکرد منحصربهفرد است که از فلسفه اصلی تی-کافی یعنی ترکیب منابع مختلف اطلاعات استفاده کرده و آن را به سطح بالاتری میبرد. این ماژول به شما امکان میدهد همردیفیهای تولیدشده توسط چندین الگوریتم مختلف (مانند MUSCLE، MAFFT، ClustalW، ProbCons و غیره) را ترکیب کنید تا به یک همردیفی اجماعی با کیفیت بالاتر برسید. ایده اصلی این است که هر الگوریتم نقاط قوت و ضعف خاص خود را دارد و ترکیب آنها میتواند به نتایج بهتری منجر شود. M-Coffee با استفاده از روش وزندهی هوشمند، مناطقی که اکثر الگوریتمها درباره آن توافق دارند را شناسایی کرده و به آنها وزن بیشتری میدهد. این رویکرد “خرد جمعی” اغلب به همردیفیهایی با دقت بالاتر نسبت به استفاده از یک الگوریتم منفرد منجر میشود.
🟪 در مجموع، این نسخههای تخصصی نشان میدهند که قدرت واقعی T-Coffee نه تنها در الگوریتم اصلی آن، بلکه در چارچوب انعطافپذیرش (Flexible Framework) نهفته است که امکان ادغام انواع دادههای بیولوژیکی را برای حل مسائل پیچیده فراهم میکند.
انتخاب یک ابزار MSA، اغلب یک بدهبستان (Trade-off) کلیدی بین سرعت و دقت است. در این بخش، جایگاه T-Coffee را در این طیف بررسی کرده و آن را با چند مورد از محبوبترین و پرکاربردترین رقبای اصلیاش مقایسه میکنیم.
T-Coffee دارای مزایای قابل توجهی نسبت به سایر ابزارهای همردیفسازی است. اولین و مهمترین مزیت، روش منحصربهفرد آن در ترکیب اطلاعات از منابع مختلف است که به همردیفیهایی با دقت بالاتر منجر میشود، بهویژه برای توالیهای با تشابه متوسط تا کم. دوم، توانایی آن برای ارائه امتیاز اطمینان برای هر موقعیت در همردیفی است که به محققان امکان میدهد کیفیت همردیفی را به صورت موضعی ارزیابی کنند. سوم، انعطافپذیری آن در پذیرش انواع مختلف دادهها (توالی، ساختار) و خروجی در قالبهای متنوع است. با این حال، T-Coffee محدودیتهایی نیز دارد. مهمترین محدودیت آن نیاز محاسباتی بالاست. به همین دلیل، تی-کافی برای مجموعه دادههای بزرگ (معمولاً بیش از ۱۰۰ توالی یا توالیهای بسیار طولانی) مناسب نیست و برای چنین مواردی الگوریتمهای سریعتر مانند MAFFT یا MUSCLE گزینههای بهتری هستند.
در مقایسه با سایر ابزارهای همردیفسازی، T-Coffee اغلب همردیفیهایی با دقت بالاتر تولید میکند، اما با هزینه زمان اجرای بیشتر. ClustalW، یکی از قدیمیترین و رایجترین ابزارهای MSA، سریعتر از تی-کافی است اما معمولاً همردیفیهای با کیفیت پایینتری تولید میکند، بهویژه برای توالیهای با تشابه کم. MUSCLE تعادل خوبی بین سرعت و دقت ارائه میدهد و برای مجموعههای متوسط توالی (چند صد توالی) گزینه مناسبی است. MAFFT یکی از سریعترین الگوریتمهای MSA است و میتواند هزاران توالی را در زمان معقول همردیف کند، اما دقت آن در توالیهای با تشابه بسیار کم ممکن است کمتر از T-Coffee باشد. در یک مطالعه مقایسهای معروف، تی-کافی برای توالیهای با تشابه کمتر از 50% بهترین عملکرد را نشان داد، در حالی که برای توالیهای با تشابه بالاتر، تفاوت چندانی بین الگوریتمهای مختلف مشاهده نشد.
حوزه بیوانفورماتیک به سرعت در حال تحول است و ابزارهای موفق مانند T-Coffee نیز برای پاسخگویی به چالشهای جدید و بهرهگیری از فناوریهای پیشرو، همواره در حال تکامل هستند. در این بخش، به آخرین قابلیتهای اضافهشده و چشمانداز آینده این ابزار قدرتمند میپردازیم.
T-Coffee همچنان در حال تکامل است و به طور مداوم قابلیتهای جدیدی به آن اضافه میشود. یکی از آخرین توسعهها، PSI-Coffee است که از تکنیک PSI-BLAST برای بهبود همردیفی توالیهای با تشابه بسیار کم استفاده میکند. این روش با جستجوی پروفایلهای مشابه در دیتابیسهای بزرگ، اطلاعات تکاملی بیشتری را در همردیفی لحاظ میکند. همچنین، نسخههای جدید تی-کافی از تکنیکهای یادگیری ماشین برای بهبود دقت همردیفی استفاده میکنند. نسخههای اخیر همچنین بهبودهای قابل توجهی در سرعت و کارایی حافظه داشتهاند که استفاده از نرمافزار را برای مجموعههای تا حدی بزرگتر تسهیل کرده و کارایی آن را بهبود بخشیده است.
آینده T-Coffee و همردیفسازی چندگانه توالی به سمت ادغام با تکنیکهای هوش مصنوعی و یادگیری عمیق حرکت میکند. مدلهای زبانی بزرگ (LLMs) و شبکههای عصبی عمیق که روی دادههای عظیم توالی آموزش دیدهاند، میتوانند بینشهای جدیدی برای بهبود دقت همردیفسازی فراهم کنند. انتظار میرود نسخههای آینده T-Coffee از این فناوریها بهره ببرند. روند دیگر، ادغام بیشتر انواع دادههای بیولوژیکی در فرآیند همردیفسازی است. علاوه بر توالی و ساختار، دادههای بیان ژن، اطلاعات برهمکنش و دادههای متابولیک میتوانند به بهبود همردیفیها کمک کنند. همچنین، با افزایش حجم دادههای توالی در دسترس، توسعه الگوریتمهای موازی و توزیعشده برای مقیاسپذیری بیشتر اهمیت زیادی خواهد داشت. تی-کافی با ماهیت انعطافپذیر و قابلیت ترکیب منابع مختلف اطلاعات، در موقعیت خوبی برای سازگاری با این روندهای نوظهور قرار دارد.
T-Coffee یکی از قدرتمندترین و منعطفترین نرمافزارهای همردیفسازی چندگانه توالی در بیوانفورماتیک است. قدرت اصلی آن در روش منحصربهفرد مبتنی بر سازگاری (consistency-based) است که امکان ترکیب اطلاعات از منابع مختلف را فراهم میکند و به همردیفیهایی با دقت بالاتر منجر میشود. نسخههای تخصصی مانند 3D-Coffee، R-Coffee و M-Coffee انعطافپذیری بیشتری برای انواع مختلف دادهها فراهم میکنند. با وجود نیاز محاسباتی بالا، T-Coffee همچنان یکی از بهترین گزینهها برای همردیفسازی توالیهای با تشابه کم است. امتیازدهی کیفیت موضعی همردیفی، یکی دیگر از نقاط قوت منحصربهفرد تی-کافی است که به محققان در ارزیابی اعتماد به نتایج کمک میکند. در مجموع، تی-کافی ابزاری ضروری در جعبهابزار هر متخصص بیوانفورماتیک است، بهخصوص برای مطالعات دقیق ساختار و عملکرد پروتئین، تحلیلهای دقیق تکاملی.
T-Coffee یک نرمافزار بیوانفورماتیکی قدرتمند برای همردیفسازی چندگانه توالیهای زیستی (MSA) است. این نرمافزار با استفاده از رویکردی مبتنی بر سازگاری (Consistency-based) اطلاعات حاصل از منابع مختلف را ترکیب میکند تا همردیفیهای دقیقتری ایجاد کند. T-Coffee در تحلیلهای فیلوژنتیک، شناسایی موتیفهای عملکردی و بررسی نواحی حفاظتشده در توالیهای DNA، RNA و پروتئینها کاربرد دارد.
T-Coffee برخلاف ابزارهایی مانند ClustalW و MUSCLE از روش مبتنی بر سازگاری استفاده میکند که امکان ترکیب اطلاعات از منابع مختلف (مانند الگوریتمهای دیگر یا دادههای ساختاری) را فراهم میکند. این رویکرد دقت بالاتری برای توالیهای با شباهت کم ارائه میدهد. با این حال، تی-کافی نسبت به ابزارهایی مانند MUSCLE یا MAFFT سرعت کمتری دارد و برای مجموعههای بزرگ توالی مناسب نیست.
بله، نسخهای از T-Coffee به نام R-Coffee به طور خاص برای همردیفسازی توالیهای RNA طراحی شده است. این نسخه ساختار ثانویه RNA را نیز در نظر میگیرد که برای مطالعه RNAهای غیرکدکننده و ساختارهای مهم RNA بسیار مفید است.
بله، T-Coffee یک نرمافزار متنباز و رایگان است. دو راه اصلی برای استفاده از آن وجود دارد: وبسرور آنلاین: سادهترین راه که نیازی به نصب ندارد و از طریق وبسایت T-Coffee قابل دسترس است. نسخه خط فرمان (Command-Line): نسخه کامل و قدرتمند که بر روی کامپیوتر شخصی (معمولاً لینوکس یا مک) نصب میشود و برای تحلیلهای پیچیده و مجموعه دادههای بزرگتر مناسب است.

تیم تولید محتوای گروه بیوانفورماتیک وانیار در تلاش است تا بهترین آموزشهای کوتاه در زمینه بیوانفورماتیک و زیستشناسی را تهیه نماید. صحت محتوای این صفحه توسط کارشناسان گروه بیوانفورماتیک وانیار بررسی شده است.



عضویت در مجله وانیار
جدید ترین مقالات در ایمیل شما!
با عضویت در مجله بیوانفورماتیک وانیار ، برترین مقالات را در ایمیل خود دریافت کنید.
سلام، وقت بخیر.
چطور میتونیم بهتون کمک کنیم؟ 🤓
تیم ما آماده پاسخگویی به سوالات شماست.
پشتیبانی 24 ساعته در 7 روز هفته.


